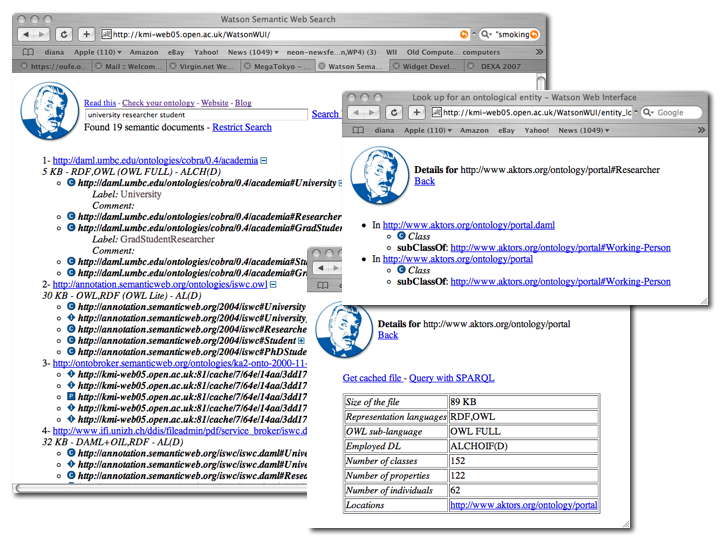
The first version of Watson, the Gateway to the Semantic Web, has just been made publicly available. Watson is a tool and an infrastructure that aims at supporting the development of a new generation of semantic web applications, which can dynamically select, combine and exploit the growing amount of semantic data and ontologies available online. Watson collects semantic content published on the Web through dedicated crawlers, analyses it to extract relevant metadata, and creates indexes to facilitate efficient search and retrieval of these semantic structures. At the time of writing, Watson has already collected and analysed tens of thousands of semantic documents, and this number is continuously growing, regularly integrating new sources of semantic content, such as FOAF files, local ontology repositories, etc.
Two interfaces are available to access the content collected by Watson, one for humans (Web search interface) and one for programs (Web services). The Web interface allows the user to employ a variety of query mechanisms, ranging from simple keyword search to SPARQL queries. In addition, a set of Web services (SOAP) and a corresponding API (Java) have been developed and made publicly available, enabling programmatic access to the knowledge collected by Watson. Using the Watson Web services and API, it is now possible to build a new kind of applications, which are truly semantic web based, as they can dynamically access and exploit distributed Semantic Web content.
Several applications relying on Watson are already being developed within KMi (for ontology mapping, folksonomy enrichment, semantic browsing, etc.) and, as Watson goes public, we expect that more and more people will adopt Watson as THE Gateway for a new generation of Semantic Web applications.
Related Links:






{kind=link}