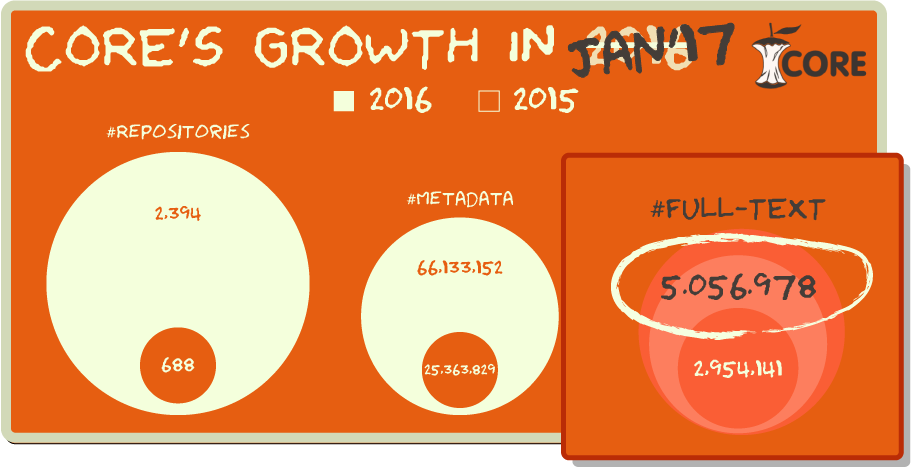
CORE, a harvesting service that aggregates open access content from open access journals and repositories from all over the world, currently provides 5 millions of open access full-text papers.
“In the last year, we have managed to scale up our harvesting process. This enabled us to significantly increase the amount of open access content we can offer to our users. With more and more open access content being made available by data providers, thanks to recent open access policies, CORE now also captures and provides access to a higher percentage of global research literature ”, says CORE’s founder, Dr Petr Knoth.
With 66 million metadata records and 5 million full-text, from 102 countries, in 52 different languages, CORE becomes now the world’s largest full-text open access aggregator. CORE embraces the vibrant collections of both institutional and disciplinary repositories, while its large volume of scholarly outputs ranges from scientific research papers, to grey literature and from Master’s to Doctoral thesis. In addition, it is a metasearch for the all the open access peer-reviewed scientific journal articles published in open access journals.
CORE’s open access collection can be accessed from our search engine (https://core.ac.uk). For those interested in using our data for other purposes, such as building services or applying text and data mining practices, we offer all the data for free via an API and a Dataset.
Related Links:






{kind=link}